思敏威集成电路完成近亿元种子轮融资
来源:纪源资本)

CiMicro.Ai宣布完成近亿元种子系列轮融资。本轮融资由知名机构东方富海、纪源资本领投、徐汇资本、德同资本、赛智伯乐等多家国资和头部市场机构跟投。
模型推理时代AI芯片性价比破局者
CiMicro.Ai成立于2025年,公司专注于大模型极致性价比推理场景,打造新一代HPU(Hyper-Cube Processing Unit)—“青衡”AI推理架构平台解决方案,深度融合SRAM存内计算、3D异质封装近存计算、自研RISC-V计算核心及复杂Chiplets芯粒系统互联等核心技术,完成全链路架构优化,精准破解传统AI计算芯片架构因计算和存储分离,导致大模型推理中遇到“存储墙”“带宽墙”等性能瓶颈,以及混合键合3D堆叠芯片工程设计中遇到“功耗墙”“散热墙”等工程复杂难题。公司依托国际领先的3D芯片工程技术,联合国产上下游产业链伙伴,坚守芯片全国产工艺供应链,致力成为大模型推理时代AI芯片的性价比破局者。
公司聚焦边缘侧及端侧大模型与Agent推理场景,积极拥抱AI基础设施及模型厂商的应用生态,提供极致性价比的大模型推理加速,推动本地智能应用落地,为AI PC、智能终端与边缘侧计算打造高效、灵活、可扩展的算力底座,赋能终端智能跃迁。公司已与知名大模型基础设施独角兽无问芯穹等知名厂商形成实际商业合作,加速AGI落地千行百业。
创始团队
公司创始团队由多位国际顶尖学者和国内领先的RISC-V/GPU芯片工程团队组成。创始团队在先进存储器件及存算一体SoC技术方向有超过10年的研究积累,超过20次流片验证存算一体IP及SoC,是最早实现2.5D/3D多芯粒存算一体AI芯片的团队,更是于2025年率先流片成功验证支持FP4浮点存内计算核心IP,近五年在集成电路领域奥林匹克级旗舰会议ISSCC与期刊JSSC发表成果11篇,突破国际领先指标。另有数十篇成果发表在芯片体系结构和电路系统顶会顶刊,如ISCA、HPCA、DAC、TCAS-I等等。创始团队成员来自Intel、AMD、华为海思以及多个国内一线AI芯片公司,有超过20年SoC芯片及系统软件研发经验,主导设计及量产交付过多款世界级芯片,芯片量产数亿颗。
创始团队寄语
CiMicro.Ai团队表示:“过去两年,全球AI行业发展主线始终围绕大模型能力的极限突破展开——参数规模不断刷新纪录,上下文长度持续延伸,多模态融合能力迭代升级等。但如果跳出‘技术能力比拼’的单一视角,切换到商业落地的宏观视角,就会发现一个更具里程碑意义的关键变化:AI行业正在告别‘重训练、轻推理’的粗放式发展阶段,迈入以‘高效推理、成本可控、规模化落地’为核心的全新周期。DeepSeek-V4的横空出世,极具颠覆性的定价策略,将推理价格降至行业平均水平1%,正是这一时代拐点的鲜明标志。各大基础模型公司将会迈入主动优化推理成本的快车道。而DeepSeek-V4通过首创CSA/HCA混合注意力架构,将百万Token长上下文纳入全系标配,同时将推理计算量降至前代的27%、长上下文压缩、低精度和稀疏化设计显存占用压缩至10%,与国产算力的深度适配,打破了海外芯片生态垄断,更是从技术侧说明当世界经济开始按Token计价,下一代AI芯片必须要重构推理架构。这正是我们选择的方向,面向大模型推理时代,CiMicro.Ai提出全新一代分布式3D存内计算融合3D近存计算HPU架构—“青衡”。HPU不仅是传统GPU/NPU的补充增强版本,而是一套围绕Token产能重新设计的大模型推理原生AI芯片架构,希望早日将高质量的大模型推理从“高价专属”走向“普惠可用”,早日进入0.01元/百万Tokens。”
东方富海表示:
“东方富海始终秉持‘以人为本,创新 + 成长’的投资理念,积极响应国家号召,坚持投早、投小、投创新。思敏威作为我们布局‘Token经济’产业链的关键一环,其聚焦的3D存算一体技术,直击AI大模型推理的‘存储墙’与‘功耗墙’核心痛点,是行业确定性演进方向。思敏威团队兼具存算技术前沿学术视野与量产工程化落地能力,成立未满一年即斩获亿元商业化订单,产业化速度领跑行业。公司自研3D存算融合HPU芯片,凭借颠覆性存算一体架构,既能弥补两代工艺差距,更从根源破解端侧 AI 推理功耗瓶颈,期待思敏威HPU芯片早日实现规模化量产,赋能全球 AI 算力自主可控与端侧智能普及。”
纪源资本表示:
“我们始终关注 AI 基础设施底层范式的结构性跃迁。在大模型进入推理驱动的新阶段后,系统瓶颈正从算力本身,逐步转向带宽、存储与能效约束,‘存储墙’与‘功耗墙’成为行业演进的核心矛盾。思敏威所聚焦的 3D 存算一体技术,正是这一代架构变革中具备明确方向性的解法之一。我们看好公司在存算融合路径上的前瞻布局,其自研 HPU 芯片通过架构层重构,有望在端侧与边缘推理场景中显著优化能效与成本结构,并在一定程度上对冲先进制程依赖。团队兼具前沿技术判断与工程化落地能力,在极短时间内实现商业化突破,验证了其执行力与产业节奏把控能力。
纪源资本将持续支持思敏威推进产品迭代与规模化量产,推动存算一体架构在新一代AI推理体系中的落地,助力更高效、可扩展的智能计算基础设施发展。”
徐汇资本表示:
“徐汇区人工智能产业规模超千亿元,区域内上千家AI企业已形成繁荣生态。思敏威集成电路的3D大模型AI推理芯片及全套解决方案将进一步夯实以‘模速空间’为核心的徐汇区生成式人工智能产业生态,助力完善区域AI产业布局。”
德同资本表示:
“德同资本坚定践行‘ALL IN AI、AI FOR ALL’战略,长期深耕 AI 基础设施与硬科技核心赛道,坚持投硬、投关键核心技术,助力国家算力自主可控与产业升级。思敏威作为我们在 AI 算力底层架构革新的关键布局,其深耕的 3D 存算一体技术,精准破解 AI 大模型推理‘存储墙’与‘功耗墙’两大行业痛点。
公司自研3D 存算融合 HPU 芯片,以颠覆性架构创新实现能效与成本双重突破,有效对冲先进制程依赖,为端侧 AI 推理提供高性价比、高可靠的国产化解决方案。
德同资本将持续全力支持思敏威加快产品迭代、生态拓展与规模化量产,推动3D 存算一体技术在 AI 推理领域深度渗透,助力构建高效、自主、普惠的新一代人工智能算力体系,赋能千行百业智能化升级。”
HPU--“青衡”架构:
围绕Token产能的系统性重构
“青衡”取意:
-
青出于蓝——在经典LPU架构基础上的跃迁
-
权衡极致——在性能、功耗、成本之间实现最优平衡
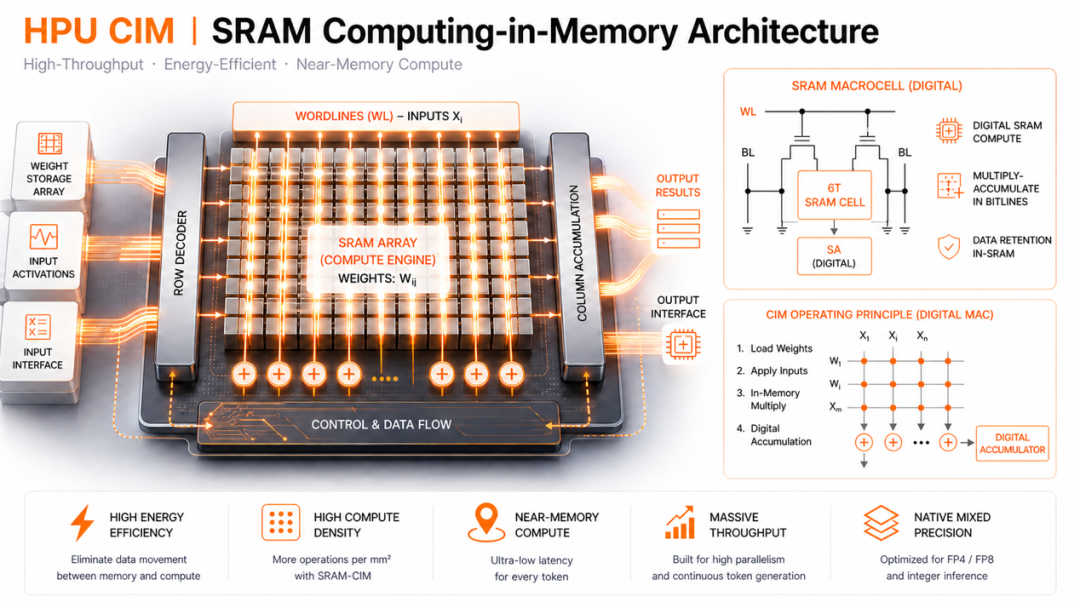
Groq LPU基于大容量片上SRAM近存计算技术,在GPGPU计算底座基础上完善了极致推理计算单元的系统拼图。而受国内工艺制程短板的掣肘,针对大模型推理的单一计算架构优化不足以形成对标海外先进水平的大模型推理性能。而融合3D异质封装近存计算、片上SRAM存算、原生FP4及极致PPA RISC-V计算核心,多Chiplets系统互联等多样的异构计算系统才是唯一可行的大模型推理国产极致性价比解决方案。HPU—“青衡”架构平台便是基于这一理念进行设计和搭建。
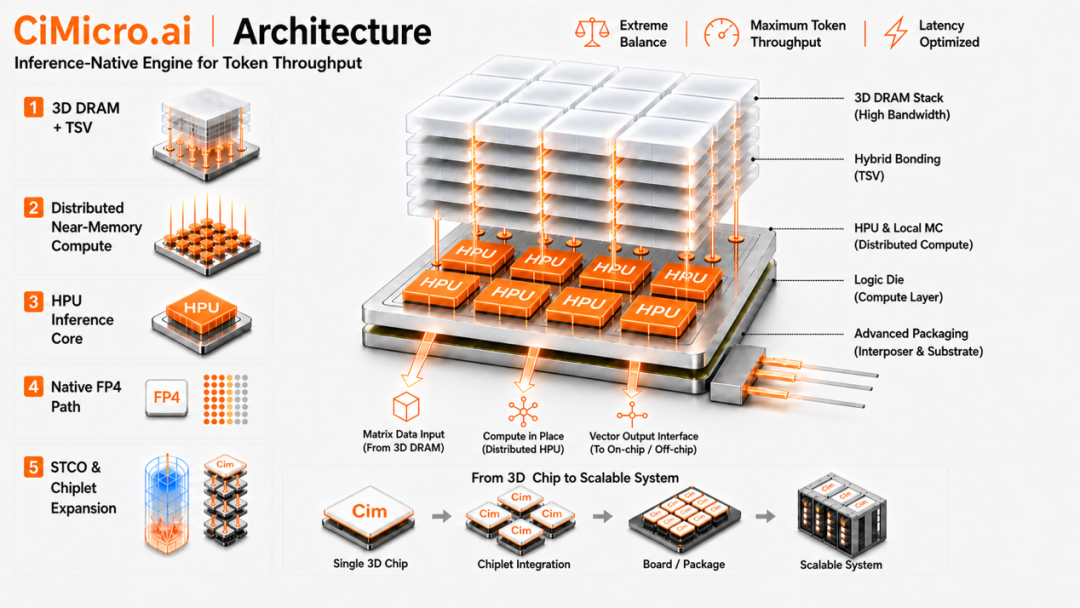
HPU—“青衡”架构不仅是传统GPU/NPU与存储颗粒的3D堆叠版本,也不仅是AI芯片单点技术的简单堆叠,而是CiMicro整合了国内先进的存内计算核心技术,打造了一整套围绕Token产能重新设计的大模型推理原生架构。从架构、存储、计算、互连、热管理和系统扩展上进行协同设计,让每一瓦功耗、每一比特带宽,都尽可能转化为高性价比且持续稳定的Token输出能力。
CiMicro.Ai:
思敏威集成电路(CiMicro.Ai)致力于成为大模型推理AI芯片的破局者,专注于存算一体融合3D异构集成封装及Chiplets芯粒互联等技术,打造HPU—“青衡”架构技术平台,聚焦边端大模型与Agent推理场景,为客户打造高效、灵活、可扩展的推理解决方案,推动Token新经济规模落地。
责任编辑: 知垚
